

Abstract
Computer vision algorithms are increasingly being applied to museum collections to identify patterns, colors, and subjects generating tags for each object image. There are multiple off-the-shelf systems that offer an accessible and rapid way to undertake this process. Based on the highlights of The Metropolitan Museum of Art’s collection this paper examines the similarities and differences between the tags generated by three well-known computer vision systems (Google Cloud Vision, Amazon Rekognition and IBM Watson). The results provide insights into the characteristics of these taxonomies in terms of the volume of tags generated for each object, their diversity, typology, and accuracy. In consequence, this paper discusses the need for museums to define their own subject tagging strategy and selection criteria of computer vision tools based on their type of collection and tags needed to complement their metadata.
Keywords
Subject tagging, image classification, museum collections, art information, computer vision, machine vision
Introduction
Computer vision is a promising technology for museum collections as these algorithms can generate data from the object images at a very fast pace. The barrier to access and use out of the box computer vision systems is getting lower and lower allowing even users with no coding expertise to use these tools. Therefore, the potential usage of these tools can be an opportunity for museums, including those with low resources, to create metadata for museum records. Adding new taxonomies can ultimately increase access to art and benefit the user experience of those online users that have limited knowledge about the subject. Users interested in birds could see all the objects tagged with this term or users could look for inspiration selecting a specific dominant color in the object. There are several experiments and proof of concepts developed by academics, and museum professionals. At present museums rely on third party algorithms, or off the shelf tools to utilize these technologies from technology companies such as Google, Amazon, Microsoft, and IBM among others. These sophisticated computer vision tools have been trained using millions of images to create an algorithm that can identify visual trends and patterns.
This paper explores the viability of this approach based on the default subject keyword tagging of the highlight artworks of The Metropolitan Museum of Art (The Met) using three computer vision systems: Google Cloud Vision, Amazon Rekognition and IBM Watson. The Met has almost half a million objects online and continues its digitization process. The object metadata includes the date, creator, culture, geography, medium, dimensions, classification, and material. However, there is no data about what is depicted in the artwork (e.g. people, nature elements, colors, objects, or emotions). There is an opportunity to include tags automatically generated by computer machine systems. However, each computer vision system has particular characteristics and training data. This paper examines the differences and similarities between the systems and in consequence, what criteria a museum should define to select a computer vision tool. The findings of this investigation have a number of important practical implications for art and culture organizations that want to apply computer vision technologies to enhance the metadata of their collections.
Literature review
Computer vision
Computer vision systems are becoming sought after tools for increasing the application, and power of machine-driven recognition. Computer vision is defined from two perspectives. From the biological science point of view, computer vision aims to come up with computational models of the human visual system. From the engineering point of view, computer vision aims to build autonomous systems which could perform some of the tasks which the human visual system can perform, and even surpass it in many cases (Huang 1996). There are widely circulated examples of this technology being adapted for diverse purposes like quality inspection of fruits and vegetables (Narendra Veeranagouda Ganganagowdar and Amithkumar Vinayak Gundad 2019), extracting regions of interest in sonar scans of the ocean floor (Labbe-Morissette and Gautier 2020), and detecting non-verbal political behavior (Jungseock Joo1, Bucy, and Seidel 2019). Other possibilities for computer vision object detection and classification include training your own machine tagging model based on edited sets of terms (either manually added, or compiled from machine models used in this study) for new images that may be added to a collection (Tomasik, Thiha, and Turnbull 2009).
Inherent in its design, and development are serious challenges regarding sensitivity, and accuracy. Recognition is necessarily a problem of discriminating between patterns of different classes. Considering the natural variation of patterns, including the effects of noise and distortions (or even the effects of breakages or occlusions), there is a tension between the need to discriminate and the need to generalize (Davies 2012). The fundamental scope of this study is about these distinctions. How can we measure immense, complex models and applications of computer vision in a way that sufficient knowledge might be obtained in a useful set of cases? Some methods will turn out to be quite unsatisfactory for reasons of complexity, accuracy, or cost of implementation, or other relevant variables: and who is to say in advance what a relevant set of variables is? This, too, needs to be ascertained and defined (Davies 2012).
Other studies which involve comparing models in areas of performance and accuracy have largely been inconclusive for illustrating a clear ‘winner’ for users. One study, completed by the U.S.-based technology and management consulting firm CapTech, presented each service (Google Cloud Vision, Microsoft Azure Computer Vision, Amazon Rekognition, Clarifai, CloudSight, and IBM Watson) with the same set of 4,800 images, distorting many to recreate real-world conditions such as blurring, overexposing or underexposing, positioning the images at odd angles, and otherwise recreating real-world conditions. CapTech evaluated the services in nine distinct areas of function and concluded that it is unlikely that any one service by itself will meet all the image recognition needs of a business or government agency. They declare in their report: ‘The six image recognition services that we evaluated are generally good, but not one is complete in itself. If you adopt image recognition services, plan on supporting multiple services and on being able to switch services quickly’ (Cox and Heinz 2017).
Subject tagging in museums collections
The usage of subject tags can increase the visibility of the museum art collection objects as people browse by topic or perform a search on the website. Particularly, it could help to increase the access for the non-experts that do not know the specific keywords to enter in the search box in order to find objects from an art collection (Smith 2006; Trant and Wyman 2006). These users represent an important proportion of Online Collection web visits (Villaespesa 2019; Walsh et al. 2020) which highlights the need to provide experiences that encourage exploration and serendipity based on other concepts and vocabularies.
Subject tags are not normally included in the collection metadata produced within the art documentation process. A few museums such as Tate or the Art Institute of Chicago have included subject searches in the user interface of their online collections. Moreover, it can have a positive effect on the Search Engine Optimization of the Online Collection and display objects as people search for specific themes on search engines. However, tagging the objects requires a lot of effort to define the vocabulary, assign the tags, review their quality and consistency across all records, and implement them live on the website. In addition, the process of digitizing is an ongoing task in the majority of museums and therefore, tagging would be a continuous requirement in this process.
Social tagging has been explored as a possibility to overcome this massive task force barrier while providing engaging experiences with online users. Examples on how to crowdsource tagging to the public include the Steve.museum project, the Brooklyn Museum, the Powerhouse Museum, and Smithsonian Photography (Chan 2007; Berstein 2008; Trant 2006). One of the conclusions of these pilot projects was that there were significant differences between the keywords coming from curatorial practice and those added by non-professionals (Trant 2006). However, these projects had important challenges; the inaccuracy of the results being the foremost concern for implementation. Another challenge is their sustainability and keeping the motivation for people to tag (Trant 2006; Berstein 2014) which may be the primary reason why none of these projects are active anymore.
Computer vision could offer a solution to the automation of this process. These algorithms can generate subject tags from the digital images of collection objects at a very fast pace and some museums such as Harvard Art Museums, the Science Museum Group, the Barnes Foundation or the Wellcome Collection are testing the ground. However, obstacles raised from these applications like taxonomies definition and accuracy of results need to be thoroughly considered (Pim 2018; Choi, Jennie 2019; Bernstein 2017; Stack 2020).
Methodology
The dataset examined via computer vision in this study included 1,323 objects from The Met’s collection. These are highlighted objects in the collection selected from each of the museum’s seventeen departments. For the purpose of the study, the highlights act as a pseudo sample size of each department, and includes a variety of objects, images, medium, classification, and culture. The data was filtered to include only those objects whose images are in the public domain.
Data collection
Data acquisition for this project was made by the API, JSON and CSV files available on the museum’s GitHub account (The Metropolitan Museum of Art n.d.). The data collection tools also included Python 2 and 3 and MacOS terminal (Code available on https://github.com/sethmbc/MACHINECOMPARISONMET). In order to implement Google, Amazon, and IBM image models on the collection a directory of high-quality images from the API was created. For this study, a Python script was utilized to pull from The Met’s website by looping through a text file of object IDs, placing them within The Met’s API URL, and then downloading the images into a directory called ImagesMET. After the image directory was successfully downloaded in a folder of about 2GB’s in size — the order in which the images were downloaded (also the same order of the text file of Object IDs) allowed us to make a new column of IDs (or aliases) in the CSV file. Later on, all three API’s return tag information with the new image IDs as keys.
As aforementioned the three computer vision systems used in this study were Google Cloud Vision, Amazon Rekognition and IBM Watson and this section presents a short summary of the process to gather the data in each case.
Google Cloud Vision
Google Cloud’s Vision API is a pre-trained machine learning model that operates through REST and RPC APIs. The model lists annotations in a JSON response that contains labels for images. The labels are built from classifications of millions of predefined categories (Google n.d.). The main functionality of the tool includes recognizing objects and faces, reading printed and handwritten text, classifying imagery, and building metadata for image catalogues (Robinson n.d.). Google Vision’s API has a byte limit for each request (>=12,000) that can be sent. The image directory needs to be broken into subdirectories that are lesser than or equal to this restriction. This can be accomplished fairly easily using a terminal. After creating an account and garnering credentials a python script was used to generate tags for the multi-level directory of images created. The results will be saved to a JSON file in the directory. Some images within the master directory could not be processed due to an error between the Google Vision system, and the listed object numbers within the Met’s CSV file, or the images themselves were not assigned a tag from the system.
Amazon Rekognition
According to the Amazon Rekognition’s API description, it identifies objects, people, text, scenes, and activities in images and videos (Fazzini n.d.). Although Amazon does not have a byte restriction like Google, they do have a total image size cap of 5MB which made 35 images not eligible. The script for Amazon Rekognition is essentially the same structure as the Google Vision but with details adjusted for documentation. We ran a Python script on our non-split image folder directory. The results were saved to the .JSON file in the directory. Some images within the master directory could not be processed due to an error between the Amazon Rekognition system, and the listed object numbers within the Met’s CSV file, or the images themselves were not assigned a tag from the system.
IBM Watson Visual Recognition
Watson Visual Recognition API has the capability to identify objects, colors, food, explicit content and other subjects from the visual content (Gong and Hill n.d.). The IBM system is straightforward with no restrictions, and the Python script is, again, a variation of the others. We used the image directories created earlier for the Google Cloud Vision system and fed them incrementally. The results were saved to the .JSON file in the directory.
Some images within the master directory could not be processed due to an error between the IBM Watson Visual Recognition System, and the listed object numbers within the Met’s CSV file, or the images themselves were not assigned a tag from the system.
The result of the application of computer vision to the museum’s collection highlights was the generation of 3,145 subject tags and 31,065 records for all the artworks in the dataset. Figure 1 shows an example of the tags generated by each of the systems for a specific artwork.

Figure 1: Tags generated for the artwork Young Ladies of the Village by Gustave Courbet
Data analysis
The data of this study was first analyzed using descriptive statistics to examine the distribution of the tags applied to the artworks. Secondly, the data was cleaned up using OpenRefine to obtain the unique tags generated by each of the systems and compare them to investigate the differences and similarities of the taxonomies. Finally, a network analysis was performed on the tags related to the objects across the three machine classifiers. Viewing the systems as a network of themes, and how they cluster in relation to one another, produces quantitative, and observational points on the spectrum of diversity, and modularity. This assists in painting a clearer picture of the qualities of each system and how they can benefit a museums individual use cases. Each unique tag, and object were transformed into nodes, with the edge count being the count of connections between both within the study. Nodes were given attributes dependent on the system they belong to (IBM Watson, Google Cloud Vision, Amazon Rekognition), and for the objects; the department to which it belongs. Using OpenOrd clustering, and Noverlap functions within Gephi, the cumulative network is sorted based on an algorithm that expects undirected weighted graphs to better distinguish clusters. The OpenOrd algorithm is originally based on Fruchterman-Reingold and works with a fixed number of iterations (Martin et al. 2011). Using five different phases: liquid, expansion, cool-down, crunch, and simmer; each stage is a fraction of the total iterations and several parameters like temperature, attraction and damping are flexible. The default mode used in this study spends approximately 25% of its time in the liquid stage, 25% in the expansion stage, 25% in the cool-down stage, 10% in the crunch stage, and 15% in the simmer stage. The network statistics were found based on filtering the different attributes, and focusing on the three separate systems.
Results
Overview: object tagging and tags distribution
The data set of this study includes 1,323 objects. Table 1 summarizes the results of the study including the number of objects that were tagged and the average of tags per object. There was not filtering based on the potential accuracy score returned by each system. The average number of tags generated for each object is very similar, being 7.78 by Amazon Rekognition and 8.34 by IBM Watson.
| Google Vision | Amazon Rekognition | IBM Watson | |
| Number of objects with tags | 1287 | 1288 | 1264 |
| Number of “null” results | 36 | 35 | 59 |
| Avg. tags per object | 8.17 | 7.78 | 8.34 |
| Total records | 10,509 | 10,018 | 10538 |
Table 1: Data summary of objects tagged
While the average number of tags per object is pretty similar, there are important differences when it comes to the distribution of the tags attributed to these objects (Figure 3). Amazon Rekognition generated the lower number of tags (721) and has the highest average of objects with the same tag. On the opposite side, IBM Watson produced 1,514 unique tags and tags were used on an average of 6.96 objects (Table 2).
| Google Vision | Amazon Rekognition | IBM Watson | |
| Number of unique tags | 910 | 721 | 1514 |
| Average | 11.54 | 13.89 | 6.96 |
| Median | 2 | 3 | 2 |
| Standard deviation | 43.2 | 50.0 | 23.3 |
| Max | 807 | 792 | 419 |
| Min | 1 | 1 | 1 |
Table 2: Descriptive statistics for the usage of the tags
The uneven size of the sections of the box plots and the high standard deviation shows that a small number of tags are used by many objects and that there is a high proportion of tags that are used only a few times. As Table 3 presents the term “art” is assigned by Google Vision and Amazon Rekognition to 807 and 792 objects respectively. Other generic terms such as “person”, “human”, “clothing”, “figure” or “painting” have been frequently applied to the objects in the dataset. However, the long tail of the tags distribution designates more specific terms. As an example, “animal” is a tag frequently applied by the three computer vision tools but specific species are assigned for particular artworks depending on the algorithm (e.g. agelaius, diplodocus, black stork or barbary sheep).

Figure 3: Box plot of the tags distribution (logarithm scale)
| Number of records | Amazon | Number of records | IBM | Number of records | |
| Art | 807 | Art | 792 | alabaster color | 419 |
| Painting | 342 | Person | 517 | person | 347 |
| Sculpture | 328 | Human | 516 | fabric | 210 |
| Visual arts | 282 | Painting | 399 | reddish brown color | 203 |
| Metal | 269 | Figurine | 303 | light brown color | 194 |
| Statue | 242 | Sculpture | 256 | clothing | 189 |
| Carving | 227 | Bronze | 223 | beige color | 188 |
| Stone carving | 214 | Statue | 205 | utensil | 187 |
| Figurine | 212 | Archaeology | 201 | supporting structure | 177 |
| Classical sculpture | 196 | Pottery | 169 | sculpture | 156 |
| Artifact | 188 | Building | 154 | artifact | 151 |
| Illustration | 148 | Rug | 152 | support | 140 |
| Stock photography | 138 | Clothing | 143 | olive green color | 122 |
| Ceramic | 123 | Apparel | 143 | figure | 111 |
| Bronze | 121 | Architecture | 139 | tapestry | 108 |
| Antique | 118 | Porcelain | 116 | indoors | 106 |
| Portrait | 105 | Furniture | 114 | protective covering | 105 |
| History | 105 | Animal | 105 | ultramarine color | 103 |
| Picture frame | 93 | Wood | 99 | paint | 91 |
| Textile | 92 | Jar | 83 | musical instrument | 90 |
Table 3: List of the twenty most frequent tags applied by each system
Taxonomies similarities and differences
Unique tags
One of the research questions of this study was to identify the similarities and differences of the tags created by these computer vision systems. The list of tags was cleaned using OpenRefine and its clustering function to combine similar words or variations of the same tag. For example, depending on the system the same tag appears in plural or singular (sport vs sports), with different spelling (jewellery vs jewelry) or similar meaning (green vs green color). The Venn diagram (figure 4) displays the tags that these computer vision algorithm results had in common. Only 122 tags were the same across all three systems and these include generic words such as paintings, sculpture, statue, furniture, rug, musical instruments, building, tapestry or vase.

Figure 4: Venn diagram showing the tags in common
In some cases, the same tag was applied to the same object (see example in Figure 5). However, the fact that tags are used by the three systems does not mean that they are always assigned to the same objects. As an example, one of the most used tags “paintings” is only applied to 32 objects consistently by all the computer vision tools.

Figure 5. Subject tags for the object Great Indian Fruit Bat
These two examples also illustrate how different the tags can be depending on the computer vision algorithm utilized. Some algorithms generate related tags for the same object, for example, Google Vision tagged the Marble head of a Ptolemaic queen (Figure 6) with both “sculpture” and “classical sculpture”. The painting “Great Indian Fruit Bat” is tagged by IBM Watson with different combinations of words related to the type of bats: brown bat, fruit bat, European brown bat, and little brown bat. Therefore, there is some repetition or redundancy in the tags that can affect the number of tags in the taxonomy applied across all collection objects and the users’ interaction with them.
 Marble head of a Ptolemaic queen (ca. 270–250 B.C.). Greek Marble head of a Ptolemaic queen (ca. 270–250 B.C.). Greek | ||
| Amazon | IBM | |
| Sculpture, Classical sculpture, Stone carving, Forehead, Art, Head, Chin, Statue, Artifact, Museum | Head, Art, Sculpture, Statue, Human, Person, Figurine, Archaeology | ancient person, person, sculpture, alabaster color |
Figure 6. Subject tags for the object Marble head of a Ptolemaic queen
Tag network analysis
| Network System | Network Diameter | Modularity | AVG. Shortest Path Length |
| IBM Watson | 8 | 0.559 | 4.110 |
| Google Cloud Vision | 8 | 0.515 | 3.472 |
| Amazon Rekognition | 11 | 0.685 | 4.152 |
Table 4: Network properties for the computer vision systems. Definitions of terms are below.
The network diameter is the longest of the calculated shortest paths within the network (Lewis and Lewis 2009).
The modularity score indicates a degree of internal network complexity. This structure, often called a community structure, describes how the network is compartmentalized into sub-networks. The value of the modularity for unweighted and undirected graphs lies in the range [-.5, 1] (Blondel et al. 2008).
The average shortest path length is calculated by finding the shortest path between all pairs of nodes and taking the average over all paths of the length thereof (the length being the number of intermediate edges contained in the path. This displays, on average, the number of steps it takes to get from one member of the network to another (Brandes 2001).

Figure 7. Google Network

Figure 8. Amazon Network

Figure 9. IBM Network
The network characteristics are not to assign quality judgments, but rather point out differences in operation that should be considered based on need. All machine classification systems within this study perform within small numerical margins of one another, and will successfully operate in most scenarios. However, some small considerations can be made by institutions depending on what they feel fits their reasoning for utilizing a machine classifier.
Google Characteristics (Figure 7):
If an organization is looking for high tag output per object (11.54), middle-ground tag uniqueness (910) and the most internal randomness around object clusters (modularity: 0.515), Google would be an efficient choice. This system is characterized by similar tags, the most random in nature and classification, being assigned multiple times across object categories (8.14).
Amazon Characteristics (Figure 8):
Amazon’s model might be for an organization looking for the most connected internal taxonomies due to the highest modularity (0.685), and the lowest number of unique tags (721). The tags are also used on average more times than the other systems (13.89). This system is characterized by the most homogeneity among its tags, and classification structure.
IBM Characteristics (Figure 9):
IBM’s model might be for an organization looking for the most tag uniqueness (1514), relatively high organization (modularity: 0.559), and the lowest amount of the same tag used per object (6.96). This system is characterized by a relatively structured classification schema, the highest tag uniqueness, and output, but with a caveat of more number of untagged objects (59).
Figures 11, 12, and 13 provide a more granular illustration of how the system tags differ around object clusters. This includes relative tag sparsity versus density, interesting examples of tag specificity, and highlighted errors among all systems.
In summary, each system has differing appeals when trying to categorize tag labels into an organization or potential taxonomy. In this case, the best approach will be reliant on the use case.
Network Details



Figure 11.
This cluster is primarily devoted to tags associated with weapons within the collection. As we can see across the three machine classifiers tags primarily make sense, but with small exceptions present within each assignment. It is also noticeable that the tag distribution is quite sparse for Amazon.
Notable Examples:
Google: Chopsticks
Amazon: Oars
IBM: Letter opener
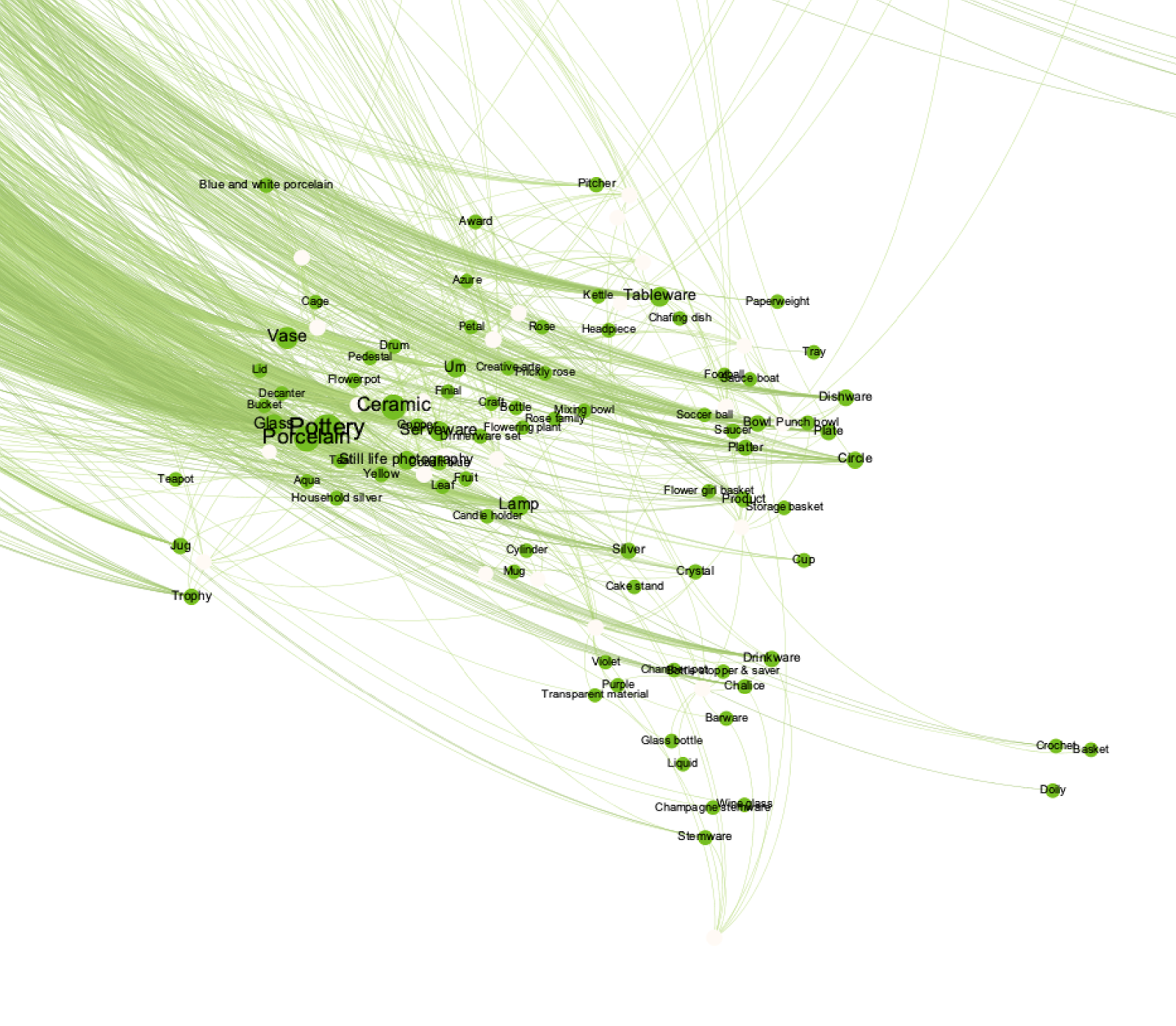


Figure 12.
This cluster is associated with pottery, and domestic ware. The tag distribution follows the curve addressed in the above network characteristics (IBM: High Return, Amazon: Low return, Google: Middle).
Notable Examples:
Google: Flower Girl Basket
Amazon: Grenade, Mouse, Computer
IBM: Rummer, Aspersorium
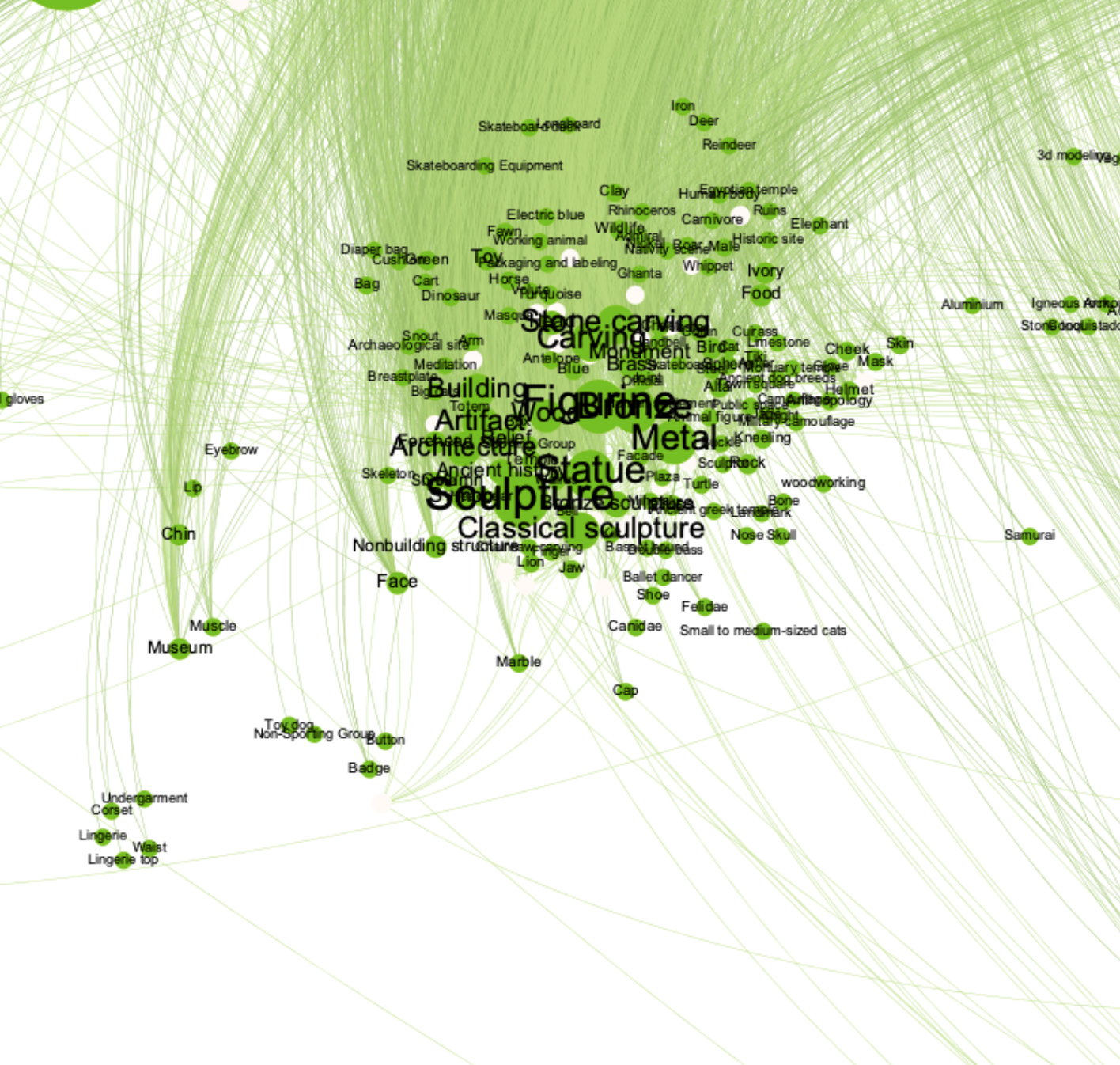


Figure 13.
This cluster is associated with antiquities and sculpture. Both Google, and IBM classifications systems are quite dense with a large number of tags occurring multiple times whereas Amazon has more evenly distributed tag occurrences across the object categories.
Notable Examples
Google: Dinosaur, Skateboarding Equipment
Amazon: Ravioli, PEZ Dispenser
IBM: Gastropod, Pallasite Meteorite
Accuracy
As presented in the literature review the main challenge of computer vision tools is the accuracy of the results. While the other sections of the paper have investigated the similarities and differences between the results based on tags distribution, semantics, and diversity within the taxonomy, this section aims to discuss the difficulties related to the correctness of the tags generated. Based on the detailed analysis of a small sample of objects in the dataset it is pretty clear that the three computer vision employed in this study returned problematic results, especially when the systems returned very specific tags. There were instances of object materials not being correct, contemporary objects being identified in medieval artworks, errors in describing the exact animal species, and attribution of the wrong context. Figure 14 illustrates examples from each of the algorithms where the tag returned was totally incorrect.
 Court dressca. 1750. British
Court dressca. 1750. British  Arched Harp (shoulder harp)ca. 1390–1295 B.C.
Arched Harp (shoulder harp)ca. 1390–1295 B.C. Jar with Dragon ca. early 15th century. Chinese Jar with Dragon ca. early 15th century. Chinese |  Bowl Emulating Chinese Stoneware9th century. Iraq Bowl Emulating Chinese Stoneware9th century. Iraq |  Shield for the Field or Tournament (Targe)ca. 1450. German Shield for the Field or Tournament (Targe)ca. 1450. German |
| Amazon Rekognition | Google Cloud Vision | IBM Watson |
| birthday cake | soccer ball | jigsaw puzzle |
 Congressional Presentation Sword and Scabbard of Major General John E. Wool 1854–55. American Congressional Presentation Sword and Scabbard of Major General John E. Wool 1854–55. American |  Antelope Head. 525–404 B.C. Egypt Antelope Head. 525–404 B.C. Egypt |  [The Salon of Baron Gros] ca.1850–57. French [The Salon of Baron Gros] ca.1850–57. French |
| Amazon Rekognition | Google Cloud Vision | IBM Watson |
| paddle | dinosaur | movie projector |
Figure 14: Table of label errors across the three systems
Conclusion
The application of computer vision technologies to The Met’s collection highlights shows a clear opportunity to generate multiple tags in an automated way that can help to describe an object and what is depicted on a visual artwork. The results of this study point to clear differences in the three systems related to the volume of tags produced and the diversity of the taxonomies. The study also raises significant challenges in terms of the accuracy of results, which need to be thoroughly considered. All three systems have different characteristics and strengths as also supported in previous studies (Cox and Heinz 2017), and the combination of the usage of these systems could serve to validate the data in the quality assurance process, or used in combination with other manual procedures such as crowdsourcing. Other computer vision systems could be added to this work such as Imagga, Microsoft Azure or Clarifai. Each system has differing appeals when trying to categorize tag labels into an organization or potential taxonomy. In this case, the best approach will be reliant on the use case. Some collections like the Harvard Art Museums have instituted using many different computer vision systems in tandem with one another to give a more holistic view of tag options for objects. If resources do not provide the option of deploying such an operation, an organization could run a similar study as the one implemented here on a small subset of objects at zero to minimal cost. This would lend sufficient data to strategize and compare which system is working best for their needs.
In conclusion, museums would need to define a strategy and selection criteria to choose which is the computer vision system that better serves their needs. Certain types of collections should consider not only machine model performance but also the state of their collections and how they relate to the type of labels generated (types of objects ie. natural history vs fine art vs. science museums). Further research work could classify the tags into specific controlled vocabularies used in museum visual documentation to get insights into the type of tags each system generates. Another potential step to validate the tags could be gathering feedback from potential users of these taxonomies on museum online collections. Ensuring the tags generated are meaningful and comprehensive is a fundamental step in making the collections more accessible and improving the user experience.
References
MetObjects.csv found publicly at https://github.com/metmuseum/openaccess/blob/master/MetObjects.csv
Cox, Jack, and Chris Heinz. 2017. “Searching for Value Amid Hype,” 26.